CS231n Lecture 4를 듣고 작성한 내용입니다. 오류 발견 시 댓글로 말씀해주시면 수정하겠습니다.
CS231n Convolutional Neural Networks for Visual Recognition
Table of Contents: Quick intro It is possible to introduce neural networks without appealing to brain analogies. In the section on linear classification we computed scores for different visual categories given the image using the formula \( s = W x \), whe
cs231n.github.io
지난 강의에서 가장 작은 loss를 만드는 가중치를 찾아가는 과정인 optimization을 할 때 사용되는 방식이 gradient descent라는 것을 배웠다. 즉, parameter를 업데이트 하기 위해서는 미분값이 필요하다는 뜻이다. 모델이 복잡해질 수록 모든 값을 하나하나 미분하는 것은 어렵다. 그래서 등장한 방식이 바로 computational graphs를 그리는 것이다.

hinge loss의 computational graphs를 그려보면 왼쪽 그림과 같다. 가중치를 곱해 손실을 계산하고, 정규화를 거쳐 결과값을 도출하는 방식이다. 이것보다 모델이 복잡해진다면 중간, 오른쪽 그림과 같이 나타나기도 한다.
그렇다면 computational graphs를 그리는 것이 왜 gradient descent를 할 때 유용하다는 것일까? 여기서 backpropagation이 등장한다. computational graphs를 그리고 backpropagation을 진행하면 쉽고 빠르게 미분을 할 수 있다.
1. Backpropagation

예시를 보며 살펴보자. computational graph에서 왼쪽부터 순차적으로 x, y, z에 값을 넣어 노드마다 값을 구한다. 이것을 forward pass라고 한다.
그런데 이제 x+y 값을 갖고 있는 (+) 노드를 q라고 정의해보자. 그렇게 된다면 f는 qz라고 할 수 있을 것이다. 그리고 q와 f에 대한 기울기를 각각 구하면 위 그림의 빨간 네모와 파란 네모에 해당한다. 그렇다면 우리가 구하고 싶은 것은 무엇인가? 바로 x,y,z에 대한 f의 기울기이다. 각 parameter에 대한 편미분 값을 얻어 gradient descent를 진행하는 것이 목적이기 때문이다.
여기서 backward pass, 즉 backpropagation이 등장한다. backpropagation이란 역방향으로 출력값을 차례대로 미분하며 기울기를 구하는 것을 의미한다. 그 과정을 정리하면 아래와 같다.
위 그림을 보면 알 수 있듯이 df/dx를 한 번에 구하는 것은 추가적인 계산이 필요하다. 바로 chain rule을 사용해 다른 미분값들을 곱해 찾아내는 방법이다. chain rule은 거창한 것은 아니고, df/dx = df/dq * dq/dx 처럼 하나의 식을 여러 식의 곱으로 분해해 표현하여 이미 아는 값들을 곱해 그 결과를 구하는 방법이다. 이 방법을 사용하면 df/dx = df/dq * dq/dx = -4 * 1 = -4가 된다. 같은 방법으로 df/dy = df/dq * dq/dy = -4이다.
전체 함수인 f의 미분값은 global gradient라고 부르며, f가 아닌 중간 노드의 미분값들은 local gradient라고 부른다.
forward pass를 하는 과정에서 local gradient를 구할 수 있다. (위에서 x, y, z에 값을 대입해 노드의 계산 결과를 찾아내던 과정이 이에 해당한다.) 따라서 이 결과들을 메모리에 미리 저장해두고, 이후 backpropagation을 진행할 때 최종 f의 미분값인 global gradient를 구한다. 그 다음 chain rule을 이용해 각 node에 해당하는 미분값을 구하고, 그 과정을 통해 각 parameter들에 대한 미분값을 구해(df/dx, df/dy, df/dx를 구했던 그 과정을 생각하면 된다.) update를 진행한다.
세미나에서 만난 예시를 추가로 첨부한다. 위의 예시처럼 숫자를 대입하지 않고 문자로도 이해해볼 수 있다. 각 게이트의 의미도 다시 한 번 꼼꼼하게 짚고 넘어가자.
위의 그림은 backpropagation을 진행한 또 다른 예제다. sigmoid function의 경우 직접 gradient를 계산할 수 있기 때문에 sigmoid gate를 하나로 묶어 직접 미분한다면 모든 gate에 대해 backpropagation을 하는 것보다 더 빠르게 값을 구할 수 있다. 이처럼 직접 미분할 수 있는 함수들을 포함하고 있다면, 이들을 모듈화해서 미분을 하는 것이 더 효율적이다.
지금까지는 scalar 값에 대한 backpropagation을 다뤘다. 그런에 gradient가 하나가 아니라 여러 개라면? vector에 대한 backpropagtion은 어떻게 이루어질까? 마찬가지로 전체 계산 흐름은 같고, gradient가 Jacobian matrix가 되는 것만 다르다.
2. Jacobian Matrix
* Jacobian Matrix란?
선형대수에서 등장하는 개념이다. n개의 변수를 가지고 있는 함수가 m개 있다고 가정해보자. 그리고 우리는 이 함수들의 편미분을 모두 구하고 싶다. 이렇게 편미분을 해야하는 변수들이 많고 그 변수들로 이루어진 함수들도 많을 때, 함수들을 하나 하나 미분하지 않아도 단순히 곱해서 더하는 형식으로 변형할 수 있는 것이 Jacobian Matrix다.
이렇게 구한 J(x,y)의 x,y에 각각 원하는 값을 넣으면 편미분을 수행한 것과 같은 결과를 얻을 수 있다. 예시의 경우 2개의 변수를 가진 2개의 함수이기 때문에 2x2의 형태로 Matrix가 만들어진 것을 확인할 수 있으며, 만약 2개의 변수에 3개의 함수라면 3x2 형태의 Jacobian Matrix가 생성된다.
이제 Vector가 입력값으로 들어온다고 가정한다. 4096 차원의 입력 벡터가 있다고 해보자. 위의 함수에서, x는 f의 최댓값과 같다.
Q1) Jacobian matrix의 크기는?
A1) Input vector * Output vector = (4096x1) * (4096*1) = 4096x4096
(추후, minibatch 학습을 하게 될 경우 input vector 크기와 output vector의 크기에 각각 batch size을 곱하게 되기 때문에 크기는 매우 커지게 된다.)
Q2) Jacobian matrix의 형태는?
A2) 대각선에 1,0이 혼재되어 있는 형태인 대각행렬
선형 함수 결과에 L2 정규화를 적용하는 예시를 살펴보자. 위에서 연습한 예제들과 입력 값이 vector라는 점만 다르다. Chain-rule을 통해 backpropagation을 수행하면 된다.
W*x를 q라고 했을 때, f(q)는 q1, q2, ... , qn의 제곱들의 합으로 표현할 수 있다. 연두색 부분처럼 편미분 값을 계산할 수 있고, 결과값을 제곱해 더함으로써 L2 결과값을 구할 수 있다.
q의 각 요소가 f의 최종 값에 얼만큼 영향을 미치는지 알아보기 위해 backpropagation을 수행해 q의 기울기를 찾아보자. q는 2차원의 벡터다. 즉, f의 기울기는 특정 qi에 대해 2qi 값을 갖게 될 것이다. 이 식을 사용해 우리가 얻은 중간 노드의 gradient는 0.44, 0.52라는 값을 갖고 있는 벡터다.
이것으로 확인할 수 있듯이 벡터의 기울기는 항상 원래 벡터와 같은 크기이고, 각각의 gradient의 요소는 이 특정 요소가 최종 결과 값에 얼만큼 영향을 미치는지를 의미한다.
이제 한 단계 더 뒤로 가서 W에 대한 기울기를 계산해보자. 위 식에 따르면, W1,1에 대한 q1의 기울기는 x1이다. 이것을 일반적으로 작성하면 첫 번째 빨간 네모 부분에 해당한다. Wi,j에 대한 qk의 기울기는 xj와 같기 때문이다. f에 대한 Wi,j의 기울기는 Chain rule을 사용해 계산할 수 있다. 그 결과 값은 두 번째 빨간 네모 부분에 해당한다.
즉, f에 대한 w의 기울기는 2q*xj고, 위의 식을 따라 W의 gradient를 계산할 수 있다. 이때, 변수에 대해 gradient가 변수와 같은 shape를 가지고 있는지 항상 체크하는 것이 중요하다.
x의 경우에도 gradient를 계산할 수 있다! 설명을 들었을 땐 이해했다고 생각했는데 다시 보니 헷갈린다. 영상을 다시 보고 정리해봐야겠다..
3. Neural Network
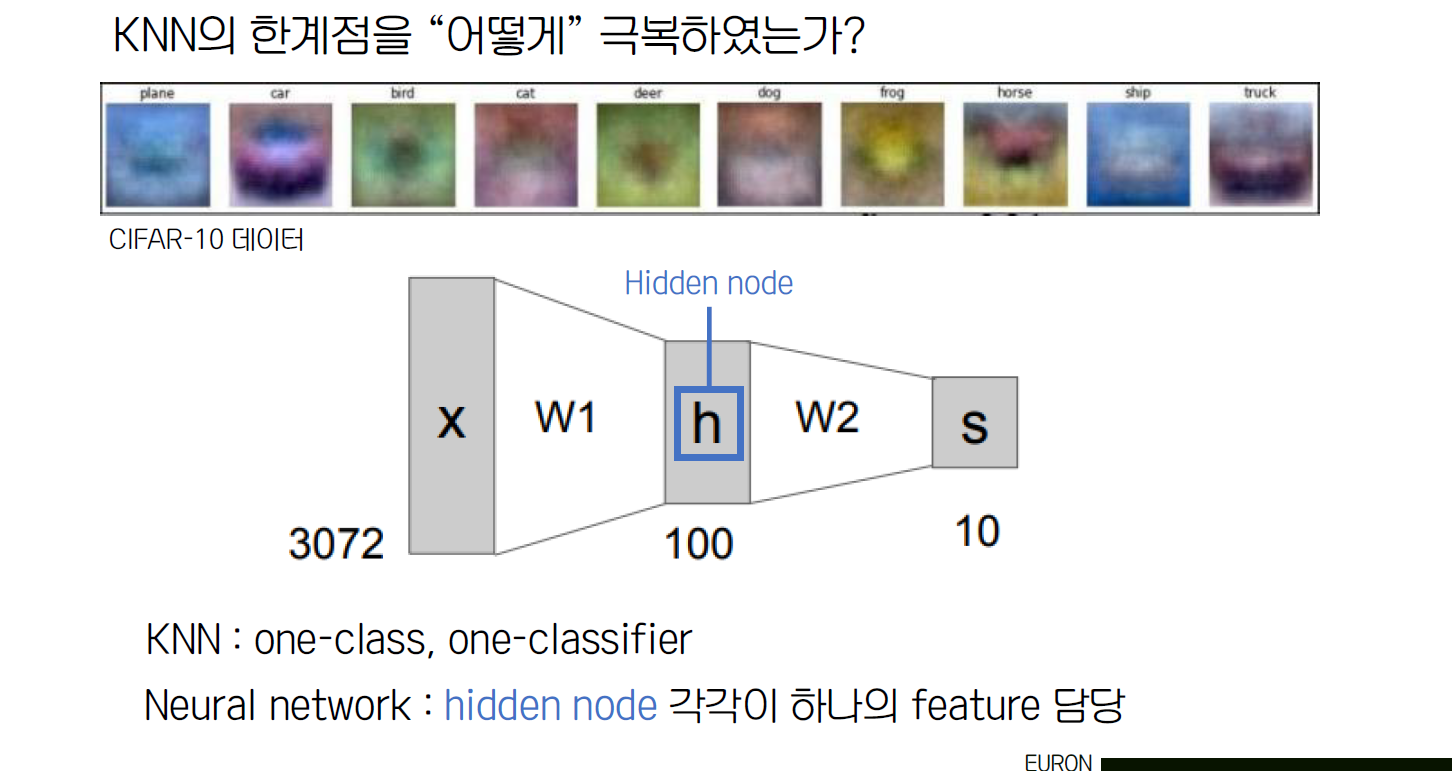
앞에서 배운 backpropagation은 Neural Network를 학습시키는데 유용하다. Neural Network란 지난 시간에 배운 linear function을 non-linear한 다른 함수에 넣어 layer을 층층으로 쌓는 방식의 딥러닝 모델이다. 왜 Neural Network에서 비선형 식들을 사용해야 할까?
Neural Network를 비유하는데 가장 자주 사용되는 생물학적 뉴런은 앞선 뉴런으로부터 받은 신호가 특정 임계치를 넘으면 그 다음 뉴런으로 신호를 보내게 된다. 이 부분에서 영감을 받아 만들어진 Neural Network 역시 activation function을 이용해 활성화할 것인지 비활성화할 것인지를 표현하게 된다. 가장 많이 사용되는 것은 ReLU라는 함수이다. (위의 그림에는 activation function의 종류 중 하나인 sigmoid 함수가 나와있다. activation functions에 대해서는 다음 강의에서 자세하게 살펴볼 것이다.)
Neural Network는 각 layer별로 여러 nodes가 존재하고, 이 nodes들이 다음 layer의 또 다른 nodes에 연결되어 있는 형태다. 각 nodes는 activation function으로 이루어져 있으며, 이전 layer에서 들여온 값을 activation function에 input으로 넘겨 값을 구하고, 이 결과 값을 다음 layer의 input으로 넘기며 계산하는 방식이다. 이때, hidden layer의 개수는 hyper parameter로 성능이 가장 잘 나올 수 있는 개수로 설정하는 것이 중요하다.

'Study > CS231n' 카테고리의 다른 글
| CS231n - Lecture 7 (Optimizer) (0) | 2021.06.06 |
|---|---|
| CS231n - Lecture 6 (Training Neural Networks I) (0) | 2021.05.14 |
| CS231n - Lecture 5 (ConvNet) (0) | 2021.05.09 |
| CS231n - Lecture 3 (Loss Functions) (3) | 2021.04.08 |
| CS231n - Lecture 2 (1) | 2021.03.30 |




댓글