앞으로 12주간 아래의 강의를 듣고 공부한 내용을 포스팅합니다.
Stanford University CS231n, Spring 2017
CS231n: Convolutional Neural Networks for Visual Recognition Spring 2017 http://cs231n.stanford.edu/
www.youtube.com
CS231n Convolutional Neural Networks for Visual Recognition
This is an introductory lecture designed to introduce people from outside of Computer Vision to the Image Classification problem, and the data-driven approach. The Table of Contents: Image Classification Motivation. In this section we will introduce the Im
cs231n.github.io
1. 😺 Image Classification pipeline
이미지 분류는 컴퓨터 비전의 가장 메인 task 중 하나
input image -> 라벨링 되어 있는 이미지군들을 사용해 들어온 이미지를 인지(카테고리에 할당)
이미지가 800x600 픽셀이면 각 픽셀은 RGB를 표현하기 위한 3자리의 수로 이루어져 있음. (매우 많은 양의 수들!) 이 수들로 라벨링된 데이터에 따라 이 이미지가 어떤 군에 속하는지 분류하는 것은 사실 매우 어려운 일. (물체가 바뀌는 것은 물론, 대상이 같아도 카메라가 움직이거나 빛의 위치가 달라지면 픽셀값이 달라진다.)
컴퓨터가 이미지를 이해하는 로직
1) train : input images and labels output a model
2) predict : input the model and make predictions for images
즉, data set(labellig 된 이미지 수집) > train(classifier을 학습시킴) > evaluate(새로운 이미지 input 후 제대로 작동하는지 판단)
이미지 classification을 위한 방법에는 어떤 것들이 있나?
1) Attempts have been made(규칙 기반 판단)
find edges(compute the edges of image) -> try to categorize all the different corners and boundaries...
규칙 기반 판단의 문제점
: 다루기 힘들고, 이 방대한 작업을 카테고리마다 전부 실행해야 함!
* view point(사진 찍은 각도)
* illumination (밝기)
* deformation
* occulusion
* background clutter (물체가 배경과 매우 흡사)
* interclass variation (여러 종이 한 이미지에)
2) Data-driven approach
- 인터넷에서 매우 많은 양의 데이터셋(이미지)를 모은다.
- 데이터들을 학습을 통해 구분하고 정리해서 모델(이러한 이미지 카테고리들을 어떻게 인식/분류하는지에 대해 학습한 지식을 요약한 것)을 만든다.
- 이 모델을 사용해 새로운 이미지를 인식한다.
=> image input이 다양하게 주어지기 때문에 일정 부분 불안정성 해소가 가능하고, 확장성이 좋아진다.
2. 💻 first classifier: Nearest Neighbor
학습된 이미지를 모두 기억하고, 새로운 이미지를 받아서 학습된 데이터들 중 가장 비슷한 이미지를 찾는다.
memorize training data > L1 함수를 이용해 training set 중 가장 비슷한 것을 찾음


Q) Nearest Neighbor를 사용하면 학습과 예측에 걸리는 시간은?
A) 학습에는 O(1), 예측에는 O(N)
모든 데이터를 비교해 예측하는 과정에 걸리는 시간이 길다. 학습에 걸리는 시간은 길어도 되지만 예측은 빨리 되어야 한다.
다양한 디바이스(모바일)로 접근하는 사용자들은 빠르게 이미지가 분류되길 원할테니까.
* dicision reasons

(K=1) 만약 input data가 첫번째 사진의 노란색 외딴섬 가장자리에 있다고 가정하면,
이 모델은 주변의 한 점만 참고해 결론을 내리기 때문에 해당 데이터를 노란색으로 분류할 것이다.
하지만 이것이 옳다고 할 수 있는가? 노란색보다는 초록색일 가능성이 더 크지 않을까?
그래서 근처 몇개의 점을 참고할건지 그 수를 조절하기 시작! K-Nearest Neighbors(k 값을 조정해 smooth한 결과값을 냄)의 등장
K-Nearest Neighbors(kNN / lazy model) : Distance Metric
* 새로운 데이터가 주어졌을 때 기존 데이터 중 가장 가까운 k개 이웃의 정보를 기반으로 새로운 데이터를 예측하는 방법 (모델을 별도로 구축하지 않고 관측치만을 이용)
* k=1은 단 1개의 이웃만 보고 예측하는 것 // k가 너무 작을 경우 overfitting, 너무 클 경우 underfitting
* 이미지를 분류하는 작업 이외에도 문장 유사도 등 다양한 것을 분류하는데 이 알고리즘을 확장해 사용할 수 있다.

| L1(Manhattan) distance | L2(Euclidean) distance |
| 두 점 차의 절댓값(거리) 나타냄. 좌표계에 따라 달라짐. | 두 점 사이의 '직선 거리' 나타냄. 좌표계의 영향 받지 않음. |
Why distance?
* 거리는 일종의 유사도(similarity)와 같은 개념
* 거리가 가까울 수록 특성(feature)들이 비슷하다는 뜻
* robust
머신러닝에서 일반화(generalization)는 일부 특정 데이터만 잘 설명하는(=overfitting) 것이 아니라 범용적인 데이터도 적합한 모델을 의미한다. 즉, 잘 일반화하기 위해서는 이상치나 노이즈가 들어와도 크게 흔들리지 않아야(=robust) 한다.
* parameters
모델 내부에서 확인이 가능한 변수로 데이터를 통해 산출 가능한 값. 학습할 때 모델에 의해 요구되는 값들
모델의 능력을 결정하며 주로 데이터로부터 학습되고 사용자가 정하지 않음
알고리즘의 최적화 과정에서 정해짐
* Parametric Model
데이터가 특정 분포를 따른다 가정
결정해야하는 파라미터의 종류와 수가 결정되어 있음
우선 모델의 형태를 결정하고 모델의 파라미터를 학습을 통해 발전시키는 방식
Training data에 대해 우리가 가지고 있는 정보를 요약하여 W에 저장
Test 할 때 실제 training data를 사용할 필요 없음
* Non – Parametric Model (대표적인 예시 : kNN)
데이터가 특정 분포를 따른다는 가정 없음 (더 flexible)
학습에 따라 튜닝할 파라미터가 명확하게 정해져 있지 않음
Data에 대한 사전지식이 전혀 없을 때 유용
더 큰 데이터를 필요로 하고 학습에 시간이 오래 걸림
❗ hyperparameters
* what is the best value of k to use?
* what is the best distance to use?
모델에서 외적인 요소로, 데이터 분석을 통해 얻어지는 값이 아니라 사용자가 직접 정하는 값이다. 모델의 parameter 값을 측정하기 위해 알고리즘 구현 과정에서 사용하며, 경험에 의해 정해지는 경우가 많아 여러 번 수행해보며 최적의 값을 찾는다.
어떤 알고리즘/hyperparameters를 선택해야 하는가?
* problem-dependent
* must try them all out and see what works best.
1) validation data

validation 데이터와 test 데이터 사이의 엄격한 구분을 두는 것은 매우 중요
* Training set: 모델을 학습시키는 data
* Validation set: 최적화 위해 Hyperparameter Tuning에 사용
* Test set: 모델의 최종 성능 평가를 위해 사용
2) cross-validation
모든 데이터를 활용함. 특정 데이터에 overfitting 되는 것을 방지. 시간이 오래 걸리기 때문에 데이터가 충분히 클 때는 사용 X

K-fold Validation
* K개의 fold로 데이터를 분류한 후 각각 한 fold의 데이터를 validation set으로 활용해 총 K번 검증하고 평균을 냄
* 모델의 성능을 전체적으로 볼 수 있음
k-Nearest Neighbor on images never used.
이유 1)
very slow at test time
이유 2)
distance metrics on pixels are not informative
* 사람의 눈으로는 다른 이미지라는 것을 인식하는데 컴퓨터는 잘 인식하지 못함..
* 그래서 정확한 결과를 얻기 위해 데이터 셋이 많을 수록 좋지만 물론 우리가 가지고 있는 데이터의 수는 제한적이기 때문에, 학습셋에 가짜 데이터(fake data)를 포함할 수 있다.
Augmentation
Training set과 현실의 test set 사이의 괴리감 존재
임의의 잡음이나 translation을 training set에 가해서 괴리감을 줄이고 성능 향상
데이터 크기가 작은 경우 데이터셋을 늘리기 위해 사용
ex) flip, noise, contrast, combination
이유 3) curse of dimensionality

kNN이 잘 작동하려면 data set이 공간 전체를 덮어야 함. dimension이 높아질수록 데이터 많이 필요 = 비효율적
the number of training examples that we need to densely cover the space grows exponentially with the dimension.
✨ summary

3. 🚀 linear classifier : SUPER IMPORTANT
딥러닝은.. 레고와도 같다. 차곡차곡.. 여러개의 linear classifier...
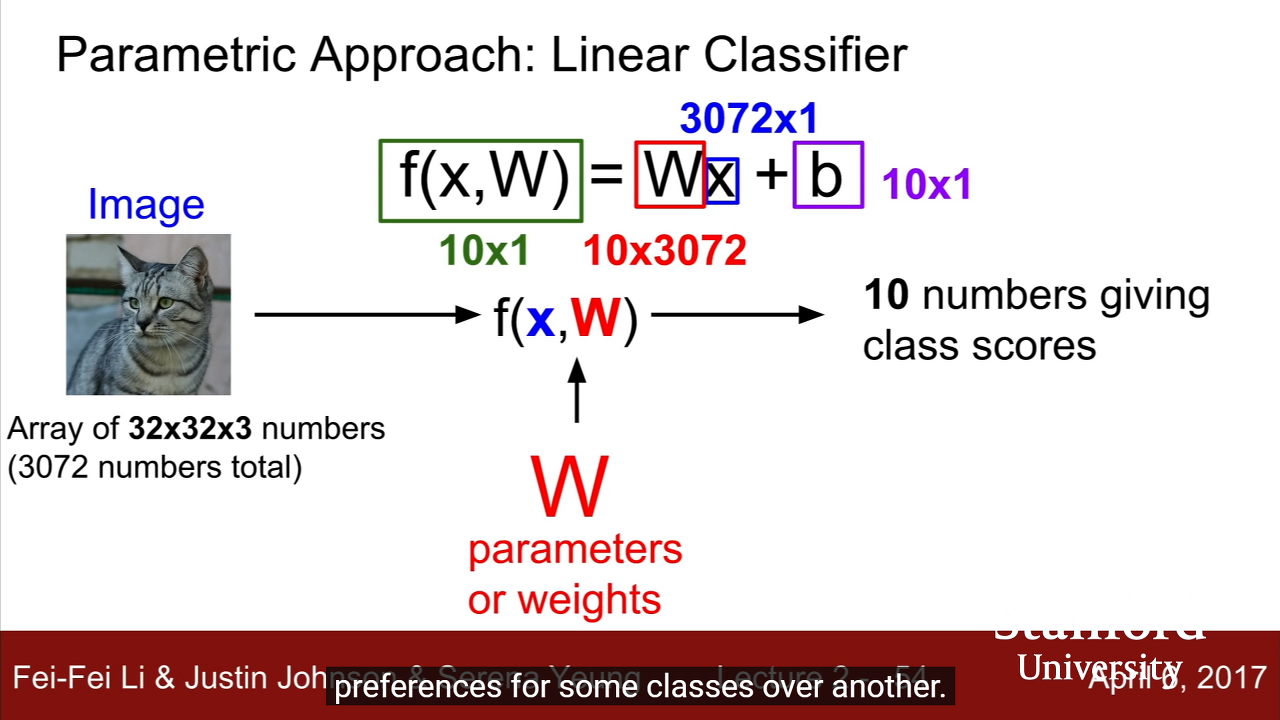
W
* Training data에 대한 정보가 요약된 벡터
* k-nearest에서는 parameter가 없고 전체 학습된 데이터를 테스트에 사용했었다.
* 하지만~ we're going to summarize our knowledge of the training data and stick all that knowledge into these parameters, W.
* 그렇게 되면 실제 training data들은 필요 없고 테스트할 때 W만 사용하면 된다는 말씀!
F
* 조건에 맞게 설정하는 함수
b
* training data와 상호작용하지 않는 상수(선형 그래프의 y절편을 움직인다고 생각하면 된다.)
* 예를 들어 고양이보다 강아지 사진이 훨씬 더 많을 경우 고양이의 편향(bias) 요소가 다른 것보다 더 높다.
example)

이미지는 3차원의 shape(RGB니까)
> 기존의 저장되어 있던 W와 곱해서
> 이미지의 pixel values들을 하나의 긴 column vector로 만들어 1차원의 값으로 만듦
> 그 후 필요에 따라 임의로 B를 더해주면
> 최종적인 score가 나온다! (각 class에 대한 score이 담긴 벡터)
'Study > CS231n' 카테고리의 다른 글
| CS231n - Lecture 7 (Optimizer) (0) | 2021.06.06 |
|---|---|
| CS231n - Lecture 6 (Training Neural Networks I) (0) | 2021.05.14 |
| CS231n - Lecture 5 (ConvNet) (0) | 2021.05.09 |
| CS231n - Lecture 4 (Backpropagation) (0) | 2021.05.09 |
| CS231n - Lecture 3 (Loss Functions) (3) | 2021.04.08 |




댓글